
Named people — PERSON entities — are among the most important things an information extraction system needs to find. Who was involved? Who signed what? Who said what to whom? Getting this right is a precondition for almost every downstream task: knowledge graph construction, due diligence, research synthesis, regulatory compliance.
We benchmarked Claude Sonnet 4.6, GPT-5.4, and Gemini 3 Pro on PERSON entity extraction across eight open-licence documents — spanning 18th-century literary prose, modern AI research papers, biomedical journal articles, and Wikipedia. Every model read each document in a single pass, with no chunking, at up to one million tokens of context. Here is what we found.
The Setup in Brief
Each document was pre-processed with a phrasal tagging step that prefixes every sentence-level phrase with a sequential marker ([Phr0], [Phr1], and so on). The model receives the full tagged document and returns structured JSON: every extracted entity must declare which phrase markers support it. This gives us provenance — we can check any extraction against the exact text it came from.
Precision is measured using a phrase-focused cross-check: for each extracted PERSON entity, we retrieve only the cited phrases and ask an LLM to rate the extraction on a 1–5 quality scale (5 = exact match, 1 = hallucinated). The weighted precision score is the mean of (score ÷ 5) across all items.
Recall is measured against a union oracle: the deduplicated set of all PERSON entities found by any model across all conditions. Matching uses soft string comparison — “Paine” matches “Thomas Paine”, “T. Paine” matches “Thomas Paine” — so surface variation does not penalise a model for using a shorter or different form of a real name. We flag this as an approximation: it favours the model that extracts the most items, and true recall requires human annotation.
Cross-checking is a second-pass verification: for each extracted entity we pass its cited phrases back to the model and ask whether the entity is genuinely supported. Items rejected in this pass are removed. This is designed to increase precision without reducing recall — since no new items are added.
Results: PERSON Entity Extraction
We evaluated 604 PERSON extractions for Claude, 784 for GPT-5.4, and 793 for Gemini 3 Pro across all documents.
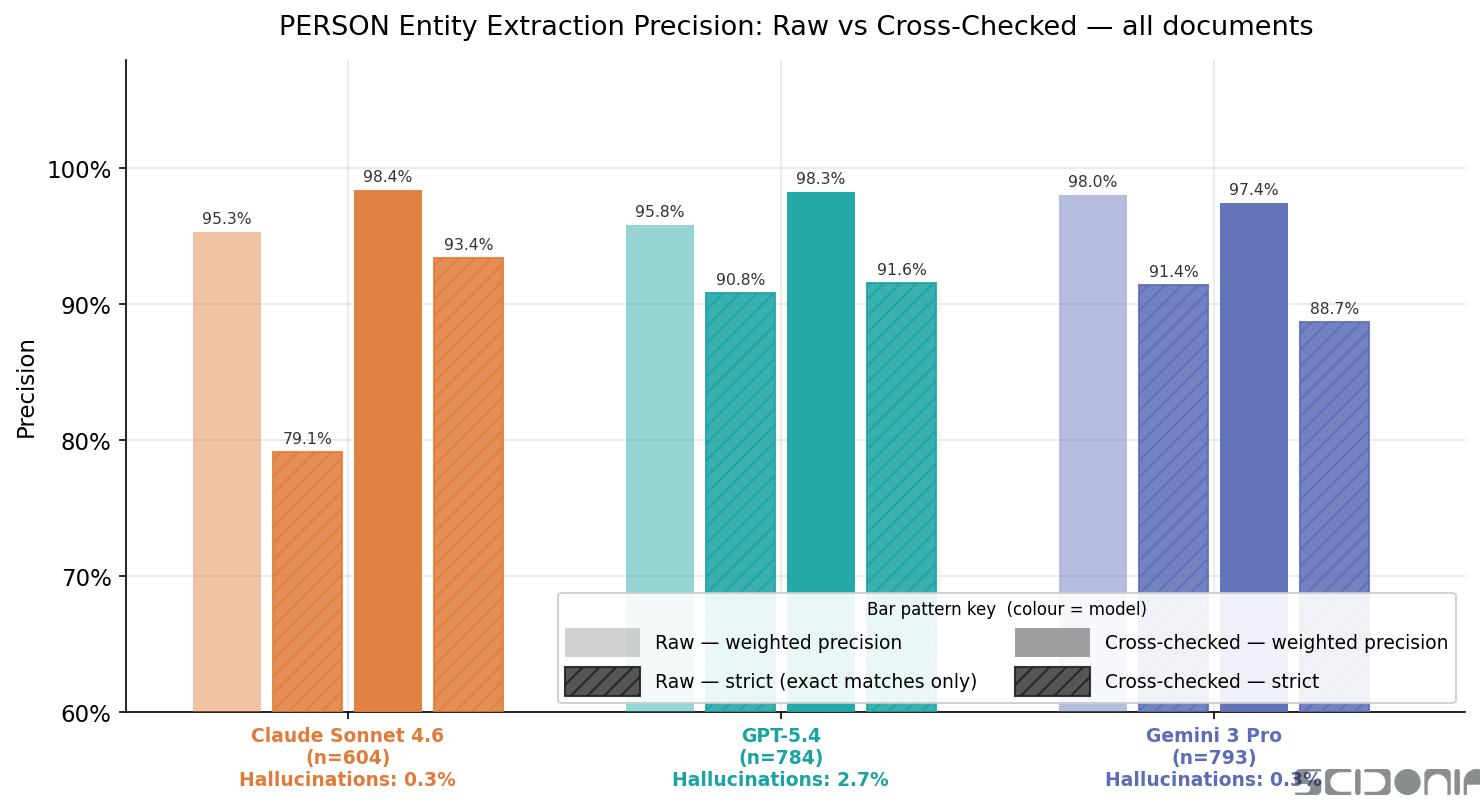
Precision
| Model | Raw weighted | Raw strict (=5) | Checked weighted | Checked strict |
|---|---|---|---|---|
| Claude Sonnet 4.6 | 95.3% | 79.1% | 98.4% | 93.4% |
| GPT-5.4 | 95.8% | 90.8% | 98.3% | 91.6% |
| Gemini 3 Pro | 98.0% | 91.4% | 97.4% | 88.7% |
Gemini starts highest. Its raw weighted precision of 98.0% is the best of the three, and its raw strict precision (91.4%) is also very strong. Notably, cross-checking barely changes Gemini’s score — it drops slightly to 97.4% weighted. Gemini trusted its own initial extractions, and that trust was largely warranted.
Claude improves the most from cross-checking. Claude’s raw strict precision — the fraction of PERSON extractions that are exact matches — is 79.1%, the lowest of the three models. After cross-checking, it reaches 93.4%: a +14.3 percentage point improvement. Claude extracts conservatively but benefits substantially from the verification pass.
GPT-5.4 sits in the middle on raw precision (95.8% weighted, 90.8% strict) and improves modestly to 98.3% weighted after cross-checking.
Hallucination Rates
| Model | PERSON hallucinations (raw) |
|---|---|
| Claude Sonnet 4.6 | 0.3% |
| GPT-5.4 | 2.7% |
| Gemini 3 Pro | 0.3% |
Hallucination — extracting a named person that does not appear in the source document at all — is rare but not zero. Claude and Gemini each hallucinate roughly 0.3% of PERSON entities. GPT-5.4’s rate is nearly nine times higher at 2.7%: across 784 extractions, that is approximately 21 invented people. Cross-checking eliminates essentially all of these, reducing GPT’s hallucination rate to near zero.
The most common form of hallucination we observed is not a completely fabricated name: it is an author or researcher referenced in a citation who is mentioned in the document but not as a substantive participant in the text. GPT tends to extract these peripheral references as full PERSON entities; Claude and Gemini are more selective.
Which Model Should You Use for PERSON Extraction?
The right answer depends on what you are optimising for.
If you want zero hallucinations and are willing to apply cross-checking: Claude or Gemini. Both have raw hallucination rates of 0.3%, and after cross-checking Claude reaches the highest strict precision (93.4%). Claude’s substantial improvement from cross-checking means the verification step is worth the additional API cost.
If you want the highest raw precision without any post-processing: Gemini 3 Pro. At 98.0% weighted and 91.4% strict, it produces the cleanest raw output. Cross-checking is optional for Gemini in a way it is not for Claude.
If you want maximum coverage and are comfortable filtering: GPT-5.4. It extracts more people (784 vs 604 for Claude on the same corpus), with the broadest recall. The 2.7% hallucination rate is manageable with a cross-check pass, which brings the noise to near zero and keeps precision above 98%.
A Note on Methodology
These results are based on eight documents across four domains (literary, scientific paper, biomedical, encyclopedic). Precision is scored by Claude Sonnet 4.6 acting as evaluator — a known limitation, as Claude may be more generous to its own extractions. Recall is measured against the union oracle, which systematically favours the model with the most extractions. Human annotation of a ground-truth reference set is planned for a subsequent study.
All code, results, and the full evaluation corpus are available at github.com/scidonia/ExtractionEval.